|
Site Sponsored By: SQLDSC - SQL Server Desired State Configuration
|
|
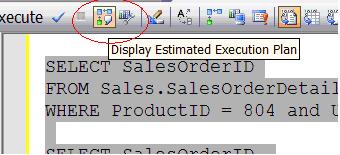
SQL Server Indexes: The BasicsBy Kathi Kellenberger on 26 November 2007 | Tags: Indexes Indexes directly affect the performance of database applications. This article uses analogies to describe how indexes work. The estimated execution plan feature of the Query Window is utilized to compare the performance of two queries in a batch. Most developers and DBAs understand that indexes on database tables enable applications and reports to run more efficiently. But, do they really know whether the database system will take advantage of an index to process a particular query or update statement? Does the order of columns specified in the index matter? What is the difference between a clustered index and a non-clustered index? To understand some index concepts, I have found it useful to use some analogies. To follow along with this article, you will need an instance of SQL Server 2005 with the AdventureWorks database installed. Each example will compare the performance of two queries in the same batch using the Graphical Estimated Execution Plan. We will focus on the "Query Cost (relative to the batch)" to compare the performance of the two queries. To see the Graphical Estimated Execution Plan, click the button shown below (Figure 1) instead of running the query.
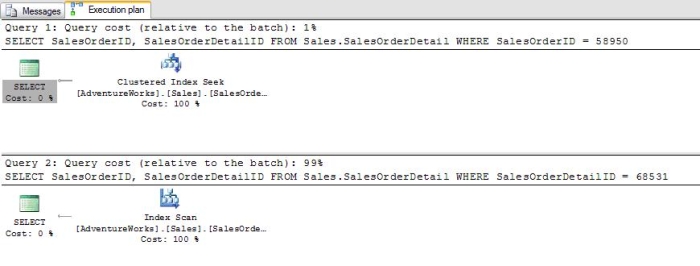
Clustered IndexesA printed phone directory is a great example of a clustered index. Each entry in the directory represents one row of the table. A table can have only one clustered index. That is because a clustered index is the actual table sorted in order of the cluster key. At first glance, you might think that inserting a new row into the table will require all the rows after the inserted row to be moved on the disk. Luckily, this is not the case. The row will have to be inserted into the correct data page, and this might require a page split if there is not enough room on the page for the new row. A list of pointers maintains the order between the pages, so the rows in other pages will not have to actually move. The primary key of the phone directory is the phone number. Usually the primary key is used as the clustering key as well, but this is not the case in our example. The cluster key in the phone directory is a combination of last name and first name. How would you find a friend's phone number if you knew the last and first name? Easy, open the book approximately to the section of the book that contains the entry. If your friend's last name starts with an "F", you will search near the beginning of the book, if an "S", you will search towards the back. You can use the names printed at the top of the page to quickly locate the page with the listing. You then drill down to the section of the correct page till you find the last name you are looking for. Now you can use the first name to choose the correct listing. The phone number is right there next to the name. It probably takes more time describe the process than to actually do it. Using the last name plus first name to find the number is called a clustered index seek. Lets say you wanted to find all the people who have the last name of "Smith" for a family reunion. How quickly could you locate all the names? Of course, it would take a matter of seconds to find all of them grouped together, possibly over a few pages. What if you wanted to locate everyone with the first name of "Jeff" in the book? Could it be done? Of course it could, but you would have to look at every entry in the entire book because the first name is the second column in our cluster key. This is called a clustered index scan, a very expensive operation on a big table. Here is an example using one of the tables in AdventureWorks. The Sales.SalesOrderDetail table has a clustered index on SalesOrderID plus SalesOrderDetailID. Take a look at the graphical estimated execution plan (Figure 2) of the batch paying particular attention to the Query cost when either the first or second column in the cluster key is used. SELECT SalesOrderID, SalesOrderDetailID FROM Sales.SalesOrderDetail WHERE SalesOrderID = 58950 SELECT SalesOrderID, SalesOrderDetailID FROM Sales.SalesOrderDetail WHERE SalesOrderDetailID = 68531
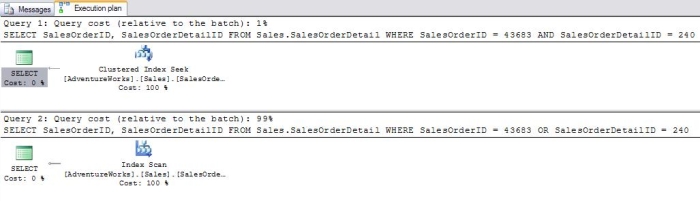
The first query in the batch will utilize a "Clustered Index Seek" while the second will use a "Clustered Index Scan". Notice that the first query will use 1% of the cost of the batch while the second query will use 99% of the cost. These results make sense when you think about the fact that the first column of the index is SalesOrderID. When trying to find a particular row based on the SalesOrderDetailID in the second query, the entire table is searched. Another search you probably wouldn't attempt with the phone directory is looking for every entry with a particular last name or a particular first name. If you wanted to find all of the entries with the first name of "Jeff" or the last name of "Smith" you would have to search every name in the book. Here is a batch illustrating this point:
SELECT SalesOrderID, SalesOrderDetailID
FROM Sales.SalesOrderDetail
WHERE SalesOrderID = 43683
AND SalesOrderDetailID = 240
SELECT SalesOrderID, SalesOrderDetailID
FROM Sales.SalesOrderDetail
WHERE SalesOrderID = 43683
OR SalesOrderDetailID = 240
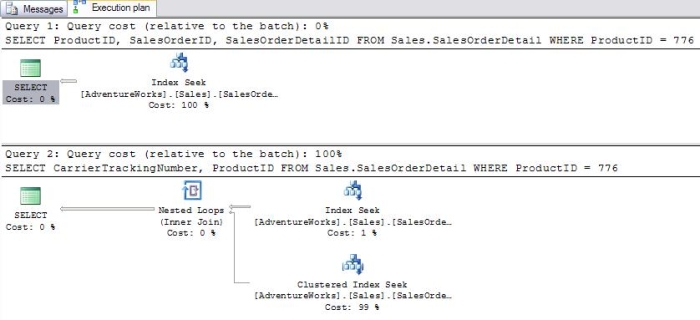
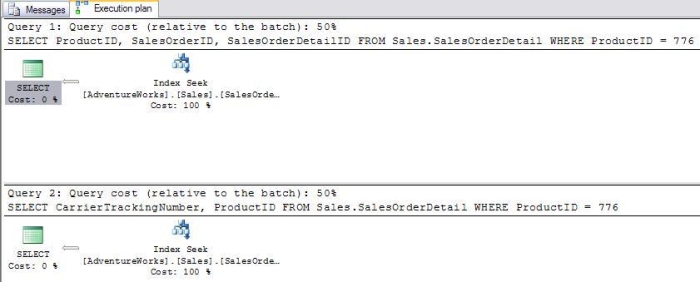
The second query using "OR" in the WHERE clause uses 99% of the resources of the batch because the entire clustered index must be scanned. Non-Clustered IndexesThe index in the back of a book is an example of a non-clustered index. A non-clustered index has the indexed columns and a pointer or bookmark pointing to the actual row. In the case of our example it contains a page number. Another example could be a search done on Google or another of the search engines. The results on the page contain links to the original web pages. The thing to remember about non-clustered indexes is that you may have to retrieve part of the required information from the rows in the table. When using a book index, you will probably have to turn to the page of the book. When searching on Google, you will probably have to click the link to view the original page. If all of the information you need is included in the index, you have no need to visit the actual data. In SQL Server 2000 the term "Bookmark Lookup" was used to describe the process of retrieving some of the columns from the actual row. In my experience, this is a very expensive operation when performed on large tables. Now "Clustered Index Seek" for tables with a clustered index, and "RID Lookup" for tables without a clustered index are the terms used. I find this very confusing since "Clustered Index Seek" is usually the preferred behavior. In Books Online, it states that when the keyword "LOOKUP" appears, it is actually a bookmark lookup. I haven't found the term displayed in the Graphical Execution plan. To see the keyword, you have to use the SHOWPLAN_TEXT option. Here is a batch and the graphical execution plan (Figure 4) when using the non-clustered index to search on the ProductID column. The second query retrieves a column that is not included in the index key: SELECT ProductID, SalesOrderID, SalesOrderDetailID FROM Sales.SalesOrderDetail WHERE ProductID = 776 SELECT CarrierTrackingNumber, ProductID FROM Sales.SalesOrderDetail WHERE ProductID = 776
The first query cost is 0% of the batch. In this case the ProductID is retrieved from the index -- no need to look at the actual table. The SalesOrderID and SalesOrderDetailID are not defined in the index, but are automatically included since they comprise the primary key. The second query in the batch costs 100% of the resources. Even though we are searching on an indexed column, we must retrieve the CarrierTrackingNumber from the actual table. Surprisingly, a "Clustered Index Seek" is the most expensive part of the query. To see why, run the following: SET SHOWPLAN_TEXT ON GO SELECT CarrierTrackingNumber, ProductID FROM Sales.SalesOrderDetail WHERE ProductID = 776 Instead of executing the query, the execution plan is returned in text format (results abbreviated). The "LOOKUP" keyword designates that a bookmark lookup was used.
|--Clustered Index Seek
...
LOOKUP ORDERED FORWARD)
In the previous example, if the CarrierTrackingNumber was part of the index, the performance issue would be solved. Run this script to modify the index: USE [AdventureWorks] GO DROP INDEX [IX_SalesOrderDetail_ProductID] ON [Sales].[SalesOrderDetail] WITH ( ONLINE = OFF ) GO USE [AdventureWorks] GO CREATE NONCLUSTERED INDEX [IX_SalesOrderDetail_ProductID] ON [Sales].[SalesOrderDetail] ( [ProductID] ASC, [CarrierTrackingNumber] ASC ) Now when the query batch is run, the second query has the same cost as the first query because the CarrierTrackingNumber is now part of the index. The table doesn't have to be accessed. Below is the graphical execution plan (Figure 5):
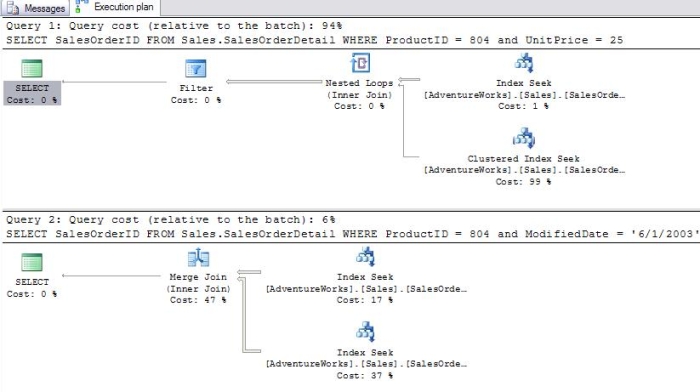
When all of the required columns are part of the index, it is called a "covering index". An index key can contain up to 16 columns and can be up to 900 bytes wide. SQL Server 2005 has a new feature to create indexes that surpass these limits called "included columns". This allows you to include additional columns in the index over the 16 column limit or columns that would be too large to include. While you can only have one clustered index per table, you can have up to 249 non-clustered indexes per table. If you ever have that many, rest assured, you have a design problem! An important thing to keep in mind is that while indexes can improve the performance of queries, indexes take up disk space and require resources to keep updated. If a table has four non-clustered indexes, every write to that table requires four additional writes to keep the indexes up to date. One more interesting thing about non-clustered indexes is that SQL Server can use them in combination or along with the clustered index. The SalesOrderDetail table has a non-clustered index on the ModifiedDate column. This query batch shows the difference when a WHERE clause has two conditions. In the first query, there is no index on the second column used in the WHERE clause. In the second query, there is a separate index on each index in the WHERE clause. In this case, the SQL Server uses the two indexes in combination to process the query, and the performance of the second query is much better (Figure 6). SELECT SalesOrderID FROM Sales.SalesOrderDetail WHERE ProductID = 804 and UnitPrice = 25 SELECT SalesOrderID FROM Sales.SalesOrderDetail WHERE ProductID = 804 and ModifiedDate = '6/1/2003'
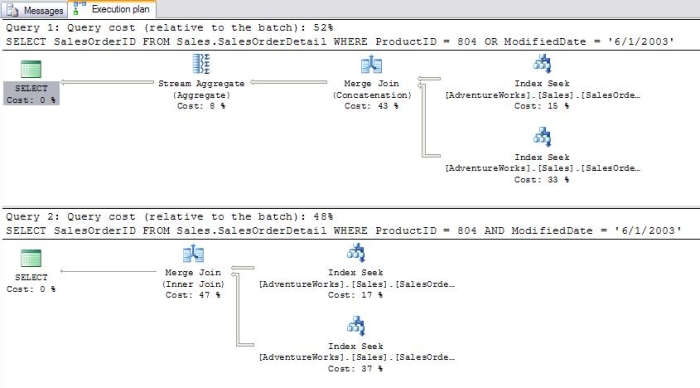
Recall how using the "OR" operator with a clustered index caused a clustered index scan. If there are individual indexes defined on two columns used in a WHERE clause with "OR", the performance is about the same as when "AND" is used. Here is an example comparing "AND" and "OR", and the costs are almost evenly divided (Figure 7): SELECT SalesOrderID FROM Sales.SalesOrderDetail WHERE ProductID = 804 OR ModifiedDate = '6/1/2003' SELECT SalesOrderID FROM Sales.SalesOrderDetail WHERE ProductID = 804 AND ModifiedDate = '6/1/2003'
There are two more issues to consider concerning indexes and WHERE clauses. What happens when a function is used in the WHERE clause? In that case, the index will not be used because the function will have to be applied to every row in the table. What happens when a wildcard is used in the WHERE clause? In this case it depends on where the wildcard is located. If the first character of the search term is replaced with a wildcard, the index will not be used and a table scan will result. Think about our phone directory example for a minute. How easy would it be to find an entry if you did not know the first letter of the last name? ConclusionStrategically placed indexes can make a huge difference in the performance of an application, especially over time as the amount of data increases. It is important to remember that a clustered index is comprised of the actual rows sorted in order of the cluster key. A non-clustered index is comprised of the key columns plus a pointer to the actual rows. You can use the Estimated Execution Plan as a way to experiment. It allows you to compare two or more similar queries to see where most of the resources will be used in the batch and, therefore, which query will perform better.
|
- Advertisement - |